ИИ против Толстого: кто напишет следующую великую книгу?
Пока все увлечены генерацией картинок и болтовнёй с чат-ботами, под капотом у ИИ-моделей идёт тихая, но фундаментальная перестройка. Интересно, а с чего вообще началась эта революция? Многие думают, что с миллиардных инвестиций Microsoft в OpenAI в 2019-м. Ан нет.
Всё началось раньше — в 2017-м, когда группа учёных выбросила в мир статью с дерзким названием «Внимание — это всё, что вам нужно» (Attention Is All You Need). Они открыли дверь, а бизнес потом ворвался в неё с деньгами и мощностями. Но разве всё решается только «грубой силой» вычислений? Нет. Всё-таки ключевое — это идеи, которые рождаются в человеческих головах.
В той самой статье и была представлена архитектура трансформера, где главную роль играл механизм внимания. Рекуррентные и свёрточные сети объявили устаревшими. Трансформер победил, но это не значит, что про старые подходы забыли. Они тихо эволюционировали в тени. Одна из таких «тихих» архитектур — SSM (State Space Models). Она выросла из серьёзной математики теории управления и может похвастаться кое-чем ценным: потрясающей эффективностью.
Два ящика: трансформер против SSM
Давайте-ка я объясню разницу наглядно. Представьте два ящика для обработки текста. У первого — широкий пасть-вход, в который можно запихнуть целый абзац сразу. Это трансформер. У второго — узенькая щель, куда текст подаётся буквально по одной букве. Это SSM.
Допустим, у нас есть длиннющая лента текста. Чтобы скормить её трансформеру, ленту режут на куски и заталкивают эти куски внутрь. Ящик «пережёвывает» каждый кусок, учится на нём и меняется. А чтобы накормить SSM, резать ничего не надо — просто медленно, буква за буквой, проталкиваем ленту в щель. Медленно? Да. Зато лента может быть бесконечной.
Конечно, это грубая аналогия. В реальности SSM не настолько медлительна. Но суть она передаёт: трансформер видит весь контекст сразу и легко находит связи между словами в разных его частях. SSM такой роскоши лишён — его «память» устроена иначе. Но зато он гораздо экономичнее. Если бы удалось научить SSM так же шустро работать с контекстом, как трансформер, гонка была бы окончена.
Эффективную систему использовать нужно, но как при этом не растерять все возможности? Современный ИИ развивается по принципу «перекрёстного опыления»: архитектуры воруют лучшие фишки друг у друга, рождая гибриды.
Рождение гибридов: лучшее из двух миров
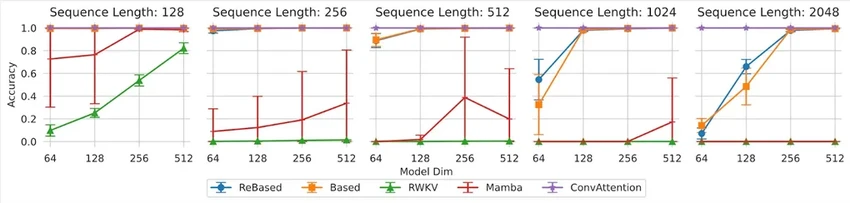
Взгляните на модель Based от стэнфордских учёных (декабрь 2023). Это так называемый линейный трансформер — попытка сделать модель эффективной, как SSM, но не потерять в умении работать с контекстом, как трансформер. И у них получилось — модель стала лучше находить ассоциации (скажем, связывать описание персонажа с его именем). Хорошее начало.
А следующий шаг сделали исследователи из T-Bank AI Research. Они создали модель ReBased, залезли под капот к Based и там всё… ускорили и отполировали. Главное их достижение — более быстрый и точный ассоциативный поиск внутри длинного текста.
Вот в чём парадокс: SSM отлично обрабатывает длинные последовательности (целые романы!), но плохо в них ориентируется. А трансформер отлично ориентируется, но с длинными текстами начинает тормозить и жрать энергию. Гибрид, сочетающий слои и трансформера, и SSM, мог бы стать золотой серединой. Способен ли он породить нового цифрового Толстого? Вопрос философский. Для шедевра мало просто уметь обрабатывать «Войну и мир». Нужна искра, смысл, душа. Но фундамент для технической возможности — мы его закладываем прямо сейчас.
В топе