ИИ скоро останется без чтения: человеческий контент для обучения иссякнет
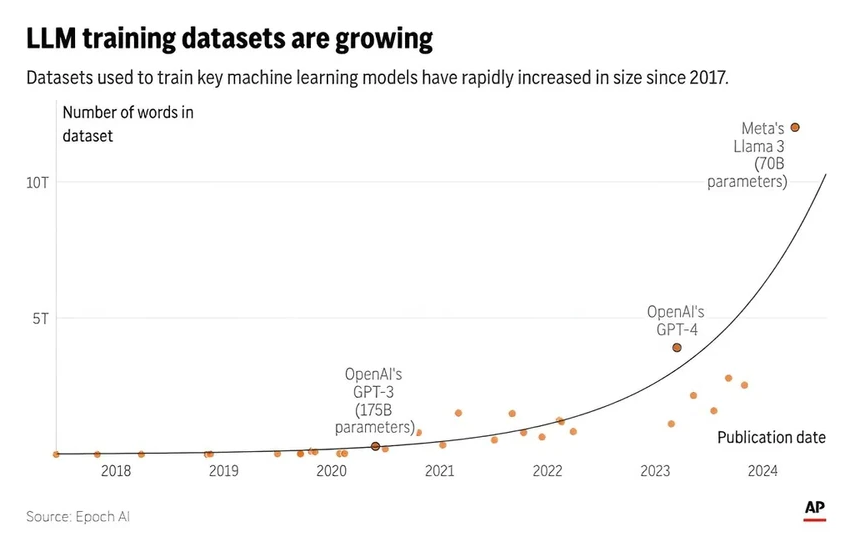
Согласно отчёту Epoch, технологическим гигантам грозит настоящий голод данных. Запас общедоступных текстов, книг, статей и постов, на которых тренируются модели вроде GPT, может быть исчерпан где-то между 2026 и 2032 годами.
Держитесь за стулья: объёмы вычислений растут примерно вчетверо каждый год, а аппетиты моделей к данным — в 2,5 раза. И вот на этом перекрёстке мы и упираемся в тупик. Самый ценный ресурс — человеческая мысль, запечатлённая в тексте, — конечен.
На чём же тогда будет учиться ИИ? Вариантов, честно говоря, немного. Первый — конфиденциальные данные: ваши письма, сообщения, звонки. Но готовы ли вы отдать свою переписку на растерзание алгоритмам? Вопрос риторический. Второй путь — «синтетические данные», то есть тексты, которые ИИ генерирует сам для себя.
И вот тут начинается самое интересное. Что, если ИИ начнёт учиться на собственных выдумках? Учёные опасаются «коллапса модели» — ситуации, когда система будет бесконечно тиражировать и усиливать свои же ошибки и предубеждения, словно в кривом зеркале. Представьте, что вы изучаете историю по учебнику, который сами же и написали, не выходя из комнаты.
Цифры поражают: самая крупная версия модели Llama 3 была обучена на 15 триллионах токенов — фрагментов слов. Это невообразимый объём, но и его скоро будет мало.
Некоторые эксперты, как, например, Николас Паперно из Университета Торонто, видят выход не в гонке за масштабом, а в специализации. Зачем обучать одну гигантскую модель на всём подряд, если можно создавать более узкие, но эффективные системы для конкретных задач?
Пока же индустрия идёт проторённым путём: сначала создаётся монстр вроде Llama 3, а затем его «доучивают» для конкретных нужд. Но сможем ли мы сразу строить точные инструменты из ограниченных материалов? Это большой вопрос.
Драгоценные слова
Если человеческий контент останется золотым стандартом, то те, кто им владеет, станут новыми нефтяными магнатами. Платформы вроде Reddit и Wikipedia, крупные новостные архивы и библиотеки — всё это превращается в стратегическое сырьё.
«Сейчас возникает интересная проблема: мы говорим о "природных ресурсах", то есть о данных, созданных человеком. Пока это звучит как шутка, но это удивительно», — отмечает Селена Декельманн из Фонда Викимедиа. Пока Википедия остаётся открытой, но как долго это продлится в мире, где слова стоят дороже золота?
Что говорит Сэм Альтман

Генеральный директор OpenAI Сэм Альтман, чей ChatGPT стал символом этой революции, в одном из выступлений признался, что компания уже экспериментирует с генерацией «огромного количества синтетических данных».
«Я думаю, всем нужны высококачественные данные. Бывают синтетические данные низкого качества. Бывают и человеческие данные низкого качества», — сказал Альтман. Но он же выразил и глубокие сомнения: «Было бы очень странно, если бы лучший способ обучить модель — просто сгенерировать квадриллион токенов синтетических данных и скормить их обратно. Почему-то это кажется неэффективным». Слова человека, который стоит на передовой, заставляют задуматься: а не загоняем ли мы себя в ловушку, пытаясь создать разум из зеркального лабиринта?
В топе