Как учат ИИ законам физики: данные плюс теория создают учёного
Ученые создали структуру, которая позволяет оценить, насколько полезно то или иное правило для итоговой точности модели. Проще говоря, они научились взвешивать вклад человеческих знаний и сырых данных. Это помогает системам гораздо лучше справляться с настоящими научными задачами — решать головоломные уравнения или подбирать идеальные условия для химического эксперимента.
«Внедрение человеческих знаний в модель может радикально повысить ее эффективность и способность к выводам, — говорит первый автор работы Хао Сюй. — Но главный вопрос: как найти баланс между данными и правилами? Наша структура как раз помогает оценить разные типы знаний, чтобы улучшить прогнозы».
Большинство современных генеративных моделей учатся исключительно на данных, методом проб и ошибок. Но представьте, что вы учите физику, только глядя на случайные видео, без единого учебника. Вы вряд ли поймете суть законов Ньютона. Так и модели, которые видят только данные, часто не способны уловить фундаментальные законы реальности и теряются в ситуациях, выходящих за рамки их тренировочного набора.
Уроки для «цифрового студента»: как добавить здравого смысла
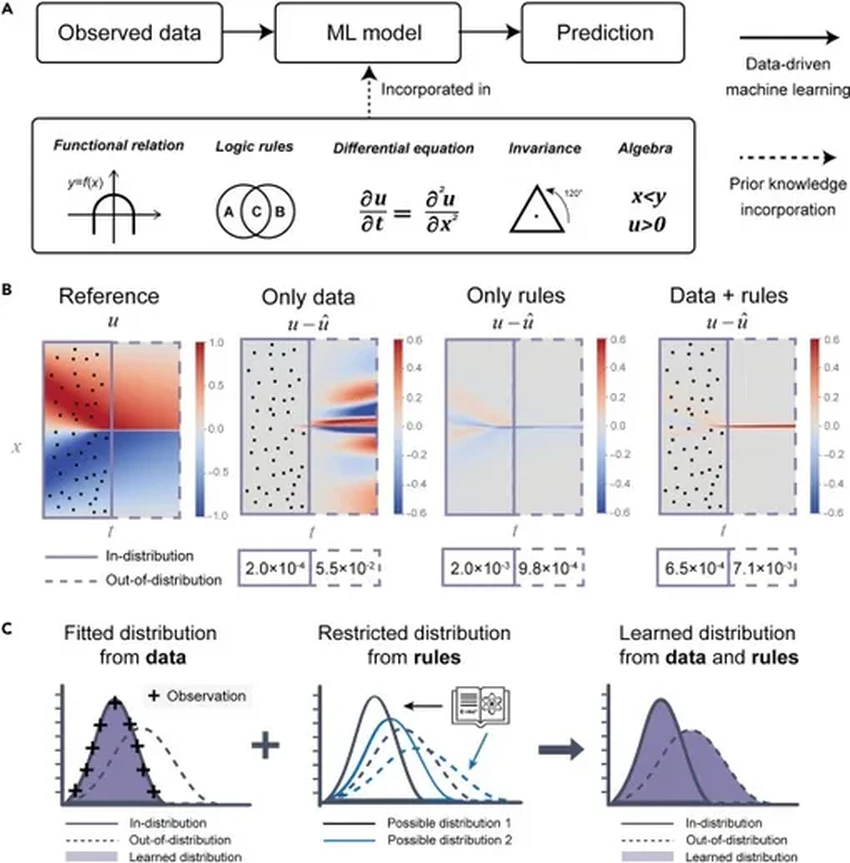
Альтернатива — так называемое «информированное машинное обучение». Идея в том, чтобы дать модели не только данные, но и набор базовых правил-подсказок. Проблема была в том, как это сделать эффективно. «Мы пытаемся научить модели законам физики, чтобы их представление о мире было более точным, — объясняет соавтор исследования Юньтянь Чен. — Это сделало бы их куда полезнее в науке и инженерии».
Чтобы раскрыть потенциал такого подхода, команда разработала систему, которая вычисляет, насколько каждое отдельное правило улучшает предсказания модели. Они также изучили, как разные правила взаимодействуют друг с другом — ведь слишком много нескоординированных указаний могут только навредить, запутав «цифрового студента».
Это позволило оптимизировать модели, тонко настраивая влияние разных правил и безжалостно отсеивая те, что противоречат друг другу или просто избыточны. «Мы выяснили, что правила связаны между собой по-разному, — говорит Чен. — И используем эти связи, чтобы ускорить обучение и повысить точность».
У такого подхода огромные перспективы в инженерии, физике и химии. Ученые уже продемонстрировали его в деле: их метод помог оптимизировать модели для решения сложных многомерных уравнений и для прогнозирования результатов экспериментов по тонкослойной хроматографии, подсказывая наилучшие условия для будущих опытов.
Исследователи планируют превратить свою разработку в удобный плагин, доступный другим разработчикам. Но их главная мечта — создать модель, которая сможет сама извлекать необходимые правила и знания прямо из данных, а не просто использовать то, что в нее заложили люди.
«Мы хотим замкнуть цикл, превратив модель в настоящего ученого, — делится планами Юньтянь Чен. — Работаем над тем, чтобы система могла самостоятельно находить знания в данных, формулировать на их основе правила и постоянно самосовершенствоваться». Звучит как начало новой, очень умной эры, не правда ли?
В топе