Как языковые модели учатся понимать редкие диалекты и наречия
Группа учёных предложила новый подход к машинному обучению. Их модель не просто поглощает информацию — она умеет целенаправленно «забывать» лингвистические данные, чтобы освободить место для новых. Это похоже на нашу способность переключаться между языками: знание основ английского и испанского помогло алгоритму быстрее схватывать структуры других языков, не начиная с нуля.
Как работает нейросеть: если очень коротко
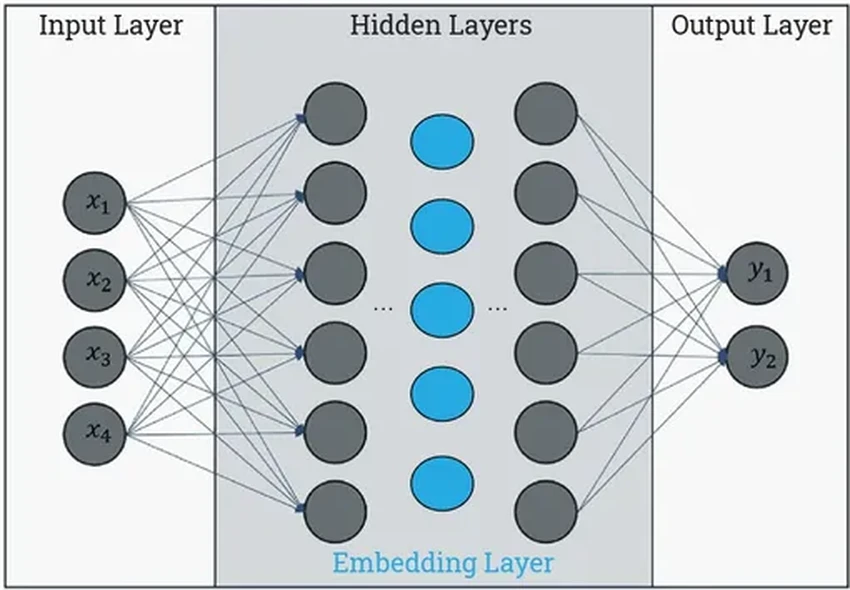
Современные языковые модели основаны на искусственных нейронных сетях. Представьте себе слои взаимосвязанных узлов — «нейронов». Каждый из них — это простая математическая функция. Он получает сигналы от соседей, что-то с ними делает и передаёт дальше, следующему слою.
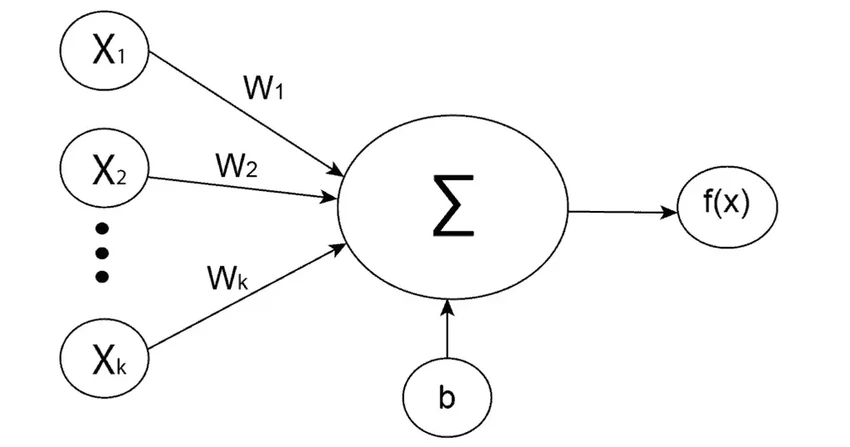
Изначально связи между нейронами слабы и почти случайны. Но в процессе обучения, пропуская через сеть тонны текстов, эти связи укрепляются и настраиваются. Например, для создания переводчика модель «скармливают» параллельные тексты на двух языках. Нейросеть постепенно улавливает, как слова и смыслы соотносятся друг с другом.
Но у такого подхода есть ахиллесова пята: он требует колоссальных вычислительных ресурсов. А если модель нужно адаптировать или добавить новый язык? «Допустим, ваша модель знает 100 языков, а вам нужен сто первый, который в неё не входил, — приводит пример соавтор исследования Микель Артече. — Начинать всё заново невероятно дорого». Знакомо, правда? Порой и нам, людям, проще выучить новый язык, чем переучиться с неправильного акцента.
Ловушка переобучения и неожиданное решение
Артече и его коллеги решили обойти это ограничение. Несколько лет назад они провели смелый эксперимент: обучили сеть одному языку, а затем буквально «стёрли» из неё параметры, связанные со словами (токенами), которые хранятся в специальном входном слое. Глубинные же слои, отвечающие за логику и понимание, остались нетронутыми. После этого они обучили модель второму языку.
Input layer (входной слой) принимает данные и передаёт их дальше. Hidden layers (скрытые слои) — это «мозг» сети, где происходит основная обработка информации. Их количество и сложность зависят от задачи.
Результат удивил: модель успешно освоила новый язык, несмотря на кажущийся конфликт в данных. Исследователи сделали вывод: входной слой хранит конкретные слова, а глубокие слои — абстрактные понятия об устройстве мира и языка. Именно это общее понимание и позволяет переключаться между наречиями.
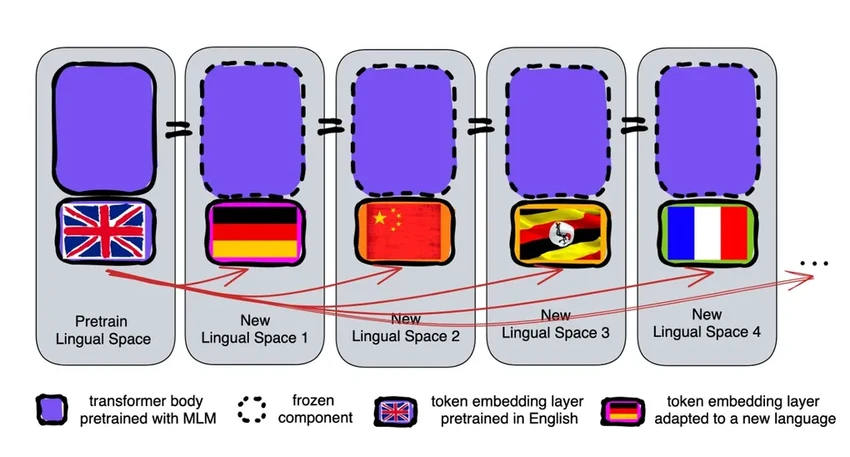
«Мы говорим на разных языках, но живём в одном мире. Яблоко — это что-то сладкое и сочное, а не просто набор букв, — поясняет ведущий автор работы Ихонг Чен. — Модель учится схватывать именно эти глубинные концепции».
Искусство забывать: главный секрет гибкого ума
Первый эксперимент доказал, что забывать полезно. Но процесс всё ещё был ресурсозатратным. Тогда учёные пошли дальше: они научили модель забывать правильно. Вместо разовой чистки входного слоя после обучения они стали периодически сбрасывать его в процессе первоначальной тренировки. Это похоже на регулярную генеральную уборку во время ремонта, а не после него.
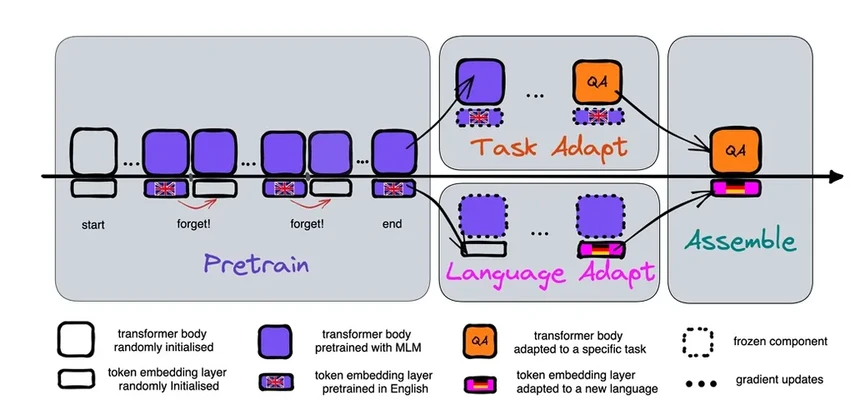
«Вся модель учится забывать, — говорит Артече. — Поэтому, когда нужно добавить новый язык, она уже готова: она знает, как освоиться с пустым входным слоем и быстро заполнить его новыми данными».
Эффект проверили на известной модели RoBERTa. После стандартного обучения и обучения с «забыванием» точность первой была чуть выше (86.1 против 85.1). Но всё изменилось, когда модели дали переучиться на новом языке с крошечным набором данных. Точность обычной модели рухнула до 53.3, а «забывчивой» — удержалась на 62.7. А когда время на переобучение резко сократили, «забывчивая» модель справилась (57.8), в то время как обычная показала результат немногим лучше случайного угадывания (37.2).
Что это говорит о понимании языка?
Регулярное забывание, судя по всему, заставляет модель искать более глубокие, абстрактные закономерности, а не просто запоминать поверхностные связи между словами. «Это делает сеть более гибкой и адаптивной», — отмечают исследователи.
Похожие процессы идут в нашем мозге. Мы не запоминаем каждый миг нашей жизни в деталях, а сохраняем суть, выжимку опыта. Адаптивное забывание — это не баг, а фича, позволяющая нам обобщать и применять знания в новых ситуациях. Перенос этого принципа в машинное обучение выглядит логичным шагом.
Этот подход открывает путь к поддержке редких языков, для которых нет миллиардов текстов в интернете. «Большие коммерческие модели часто проваливаются на моём родном баскском, — приводит пример Микель Артече. — Адаптация существующих моделей через механизм забывания — это наиболее реалистичный путь к тому, чтобы технологии заговорили на всех языках планеты, а не только на самых распространённых».
В топе