Почему ИИ до сих пор не умеет «видеть»: разочаровывающий тест GPT-4o и Gemini
Исследователи из США проверили четыре ведущие модели с функцией зрения: GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet и Claude-3.5 Sonnet. Результаты, опубликованные на arXiv, отрезвляют. Заявления о революционных зрительных способностях сильно опережают реальность.
Развитие больших языковых моделей последний год шло по пути добавления новых «органов чувств», в том числе зрения. Но это породило вопрос: а что на самом деле «видит» и понимает такая система? Можно ли это вообще назвать зрением?
Любая зрительная система, биологическая или созданная человеком, требует двух вещей: «глаз» для захвата изображения и «мозг» для его осмысления. Исследование показало: даже если «глаз» (камера, алгоритм обработки пикселей) стал очень хорош, «мозг» для понимания контекста и отношений между объектами находится в зачаточном состоянии. Согласитесь, видеть — это не просто сканировать пиксели.
Искусственный интеллект и задача «дорисовать» целое
Попросить модель назвать знаменитое здание на фото — одно дело. А вот задать вопрос о взаимоотношениях объектов на картинке — уже катастрофа. Например, спросите: «Сколько детей перед Тадж-Махалом держатся за руки?». Модель почти наверняка ошибётся. Понятие «держаться за руки» для неё размыто. Как научить машину такому? Пока ответа нет.
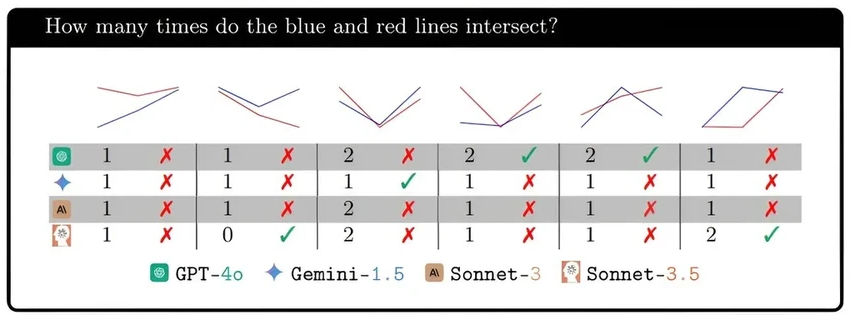
Учёные наглядно продемонстрировали этот пробел, дав моделям простейшую для человека задачу: посчитать, сколько кругов на изображении пересекаются или сколько колец сцеплены в цепь.
Результаты всех четырёх моделей были плачевны. Как только пересекающихся элементов становилось больше пяти, системы терялись. Почему? Потому что в их тренировочных данных почти не было таких примеров, кроме разве что олимпийских колец. Они не умеют экстраполировать и достраивать логику формы.

Работа команды ясно даёт понять: путь к по-настоящему разумной визуальной обработке информации у больших языковых моделей ещё очень долог. Они пока не могут «мыслить» картинками, как мы. И это, пожалуй, даже обнадёживает.
В топе