Почему мозг распознаёт дипфейк: границы синтеза искусственного голоса
Синтез голоса — одна из старейших амбиций искусственного интеллекта. Но вот что удивительно: несмотря на все триумфальные заголовки, мы до сих пор окружены лишь модификациями реальных голосов. Все «поющие» и «разговаривающие» модели в основе своей имеют записи живых людей. Нейросеть может исказить тембр, изменить интонацию, но создать с нуля убедительный, абсолютно «несуществующий» голос, который выдержал бы долгое общение, — это пока задача нерешенная. Почему же технология, рисующая невероятные изображения, спотыкается на звуке?
Именно этим вопросом задались цюрихские ученые. Они решили не спрашивать людей, а заглянуть прямо в источник восприятия — в сам мозг, чтобы увидеть разницу в его работе.
Как мозг обрабатывает голос
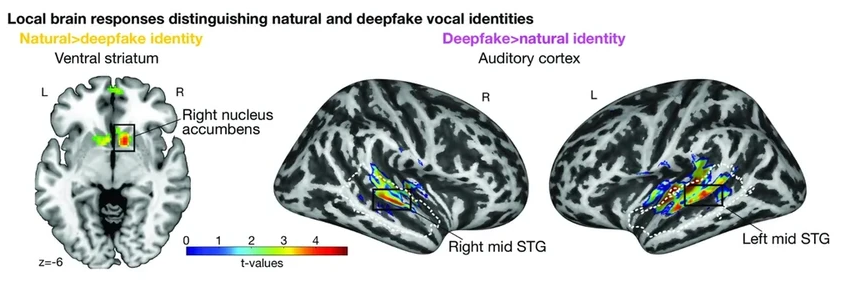
В эксперименте участвовали 25 добровольцев. Их задача была проста: определить, настоящий перед ними голос или синтезированный. Люди справлялись почти идеально. А тем временем аппарат фМРТ пристально следил за активностью их мозга. И вот что обнаружилось: паттерны активности были совершенно разными в зависимости от происхождения голоса.
Первая загадка — слуховая кора. Эта часть мозга, ответственная за первичную обработку звуков, реагировала на «фейк» иначе, чем на натуральный голос. Это значит, что современные алгоритмы синтеза где-то допускают микроскопические, но принципиальные ошибки в звучании. Ученые пока не могут точно сказать, в чем именно они заключаются, но для мозга разница очевидна. Интересно, какие именно «нотки» натуральности мы, сами того не осознавая, считываем?
Вторая область, которая выдала подделку, — прилежащее ядро (NAcc). Это наш внутренний «центр вознаграждения», который загорается, когда мы узнаем что-то приятное или знакомое. На синтезированный голос он не отреагировал. Похоже, искусственный голос лишен той самой неуловимой «души» или индивидуальности, которая вызывает у нас подсознательное чувство узнавания и доверия. Без этого «вознаграждения» убедительность голоса резко падает.
Вывод исследователей двойственен. С одной стороны, сегодня создать совершенный синтетический голос с нуля практически невозможно — наш мозг видит подвох. С другой стороны, прогресс в нейросетях настолько стремителен, что, возможно, уже завтра этот барьер будет взят. И тогда нашему внутреннему детективу придется несладко.
В топе