Токены в ИИ: как они работают и почему это важно для ваших запросов
Часто общаясь с ChatGPT или ему подобными, вы наверняка натыкались на термины «токен» и «контекстное окно». Особенно когда пытались скормить модели целую простыню текста разом. Так что же скрывается за этими словами? Как объяснил эксперт Дхармеш Шах, всё не так уж запутанно.
Токен: не слово, а его родственник
Представьте, что большая языковая модель (LLM) — это невероятно привередливый читатель. Она не поглощает слова целиком, а разбирает их на кусочки — токены. Токен — это последовательность символов, своеобразный «кирпичик» текста. Это почти слово, но часто — его часть, вместе со знаками препинания и пробелами.
Возьмем простую английскую фразу: «I don’t like flying». Для нас это четыре слова. А для GPT — вот такая мозаика:
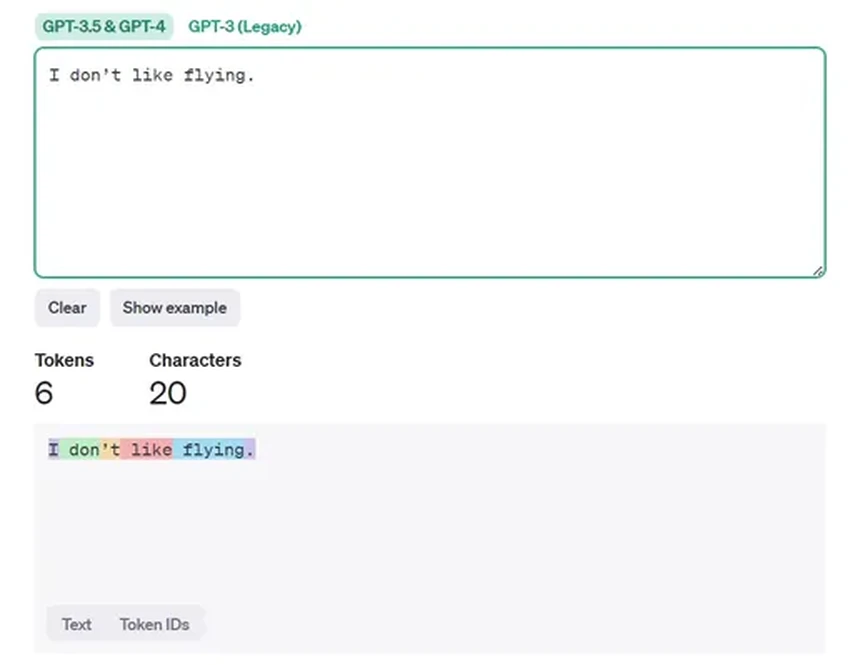
(Кстати, вы можете сами поэкспериментировать с этим в инструменте токенизации от OpenAI — это затягивает!).
А вот русский вариант: «Я не люблю летать». Казалось бы, фраза короче. Но смотрите, что происходит:
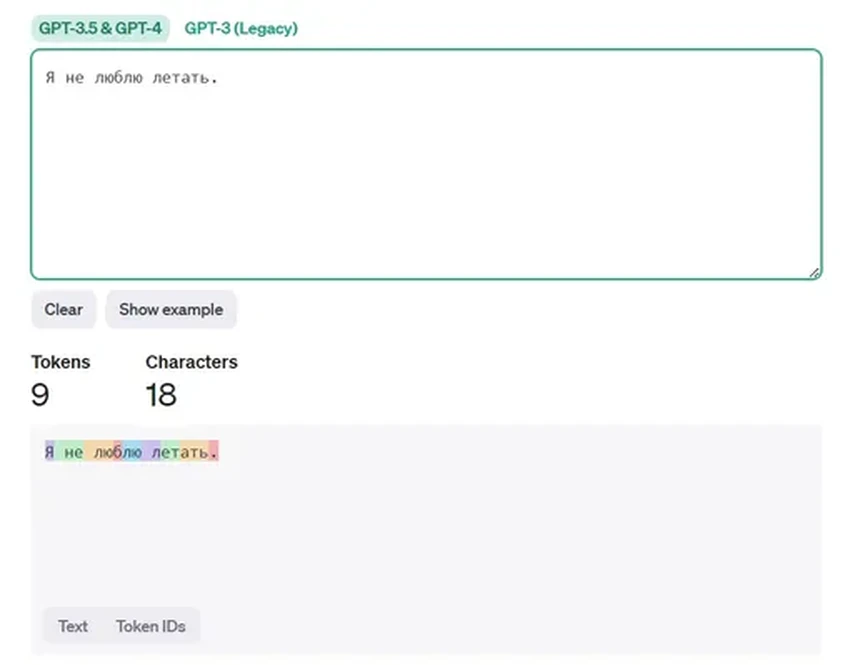
Символов меньше, а токенов — больше! Вот вам и ключевое отличие. По статистике, на 75 английских слов приходится около 100 токенов. А на те же 75 русских слов — уже 120-150. Разница-то ощутимая!
Возникает резонный вопрос: зачем эти сложности? Почему бы не работать с целыми словами? Всё дело в эффективности. Модели оперируют числами, а не буквами. Текст нужно перевести в векторы — последовательности чисел. Если каждой словоформе присваивать уникальный номер, словарь получится астрономическим. Гораздо умнее разбивать слова на переиспользуемые кусочки — те самые токены.
Например, возьмем слова: can, can’t, don, don’t. Если выделить апостроф с «t» в отдельный токен, то вместо четырех уникальных единиц нам нужно хранить всего три: can, don и ‘t. Экономия — 25%! А теперь масштабируйте это на весь язык. Представляете, насколько компактнее становится внутреннее представление текста?
«И зачем мне это знать?» — спросите вы. Да хотя бы потому, что токен — это валюта мира LLM. Все лимиты, в том числе размер контекстного окна, считаются именно в них.
Контекстное окно: память модели
Контекстное окно — это, если угодно, оперативная память модели. Туда помещается ваш запрос (промпт) и её же ответ. У каждой модели есть свой потолок, выраженный в токенах. Чем это окно шире — тем лучше. Модель может «удерживать в голове» больше деталей, инструкций и предыдущих реплик разговора.
Представьте окно размером с одно предложение. Никакого глубокого диалога не получится, верно? Вы не сможете дать детальный контекст, и ответ будет поверхностным.
Объёмы этих окон стремительно растут. Помните GPT-3 в 2023-м? Его лимит был около 4 тысяч токенов. Сейчас же Claude от Anthropic хвастается окном в 200 тысяч, а Google Gemini и вовсе заявляет о поддержке миллиона токенов. Прогресс налицо.
Зачем такие гигантские «памяти»? Представьте, что вы хотите, чтобы ИИ анализировал вашу личную переписку или внутренние документы компании — то, чего нет в его исходных данных. Если окно достаточно велико, вы можете просто «скормить» ему эти тысячи писем как контекст, и модель будет на них опираться. Это меняет правила игры.
А теперь вернемся к разнице между языками. Больше токенов на русский текст — это во многом следствие его структуры. Следующий символ в русском языке предсказать статистически сложнее, чем в английском, вот модель и дробит его мельче.
Из этого следует практический совет: если вам критически не хватает места в контекстном окне, попробуйте перейти на английский. Вы сможете «упаковать» больше смысла в то же количество токенов.
Впрочем, окна растут так быстро, что, возможно, скоро эта языковая неравномерность перестанет быть проблемой. Но пока что об этом нюансе стоит помнить. Дерзайте, и пусть ваши диалоги с ИИ будут длинными и содержательными!
В топе