Универсальный ИИ-агент учится выполнять команды в любых видеоиграх
Видеоигры — это идеальный полигон для тренировки искусственного интеллекта. Почему? Потому что они, как и жизнь, полны непредсказуемости, меняющихся условий и сложных целей. Помните AlphaStar, которая обыгрывала чемпионов в StarCraft II? Теперь следующий шаг: агент, который не просто играет, а «живет» и следует инструкциям в десятках разных игровых вселенных.
SIMA (Scalable Instructable Multiworld Agent) — первый в своём роде. Он создавался в коллаборации с игровыми студиями. Его особенность в том, что он учится следовать командам на человеческом языке, адаптируясь к уникальным правилам каждого мира. Научить ИИ играть в одну игру — уже достижение. Но если он научится понимать инструкции где угодно, это откроет путь к созданию по-настоящему полезных агентов для любой среды, виртуальной или реальной.
Работу над SIMA можно сравнить с игрой в песочнице. Только вместо куличей мы лепим будущее взаимодействия человека и машин.
Уроки в виртуальных мирах: как учат SIMA
Для обучения агента Deepmind сотрудничала с восемью студиями, включив в его «учебную программу» девять разнообразных игр — от космической саги No Man’s Sky до разрушаемого мира Teardown. Каждая игра — новый вызов. Здесь нужно уметь всё: от простой ходьбы и сбора ресурсов до пилотирования корабля или крафта предметов.
Учёные также создали четыре исследовательские среды, включая специальную «Строительную лабораторию» на движке Unity. В ней агенты учатся манипулировать объектами, строить конструкции и постигать основы физики — например, что камни падают вниз, а не вверх.
Как же связать язык с действиями? Исследователи пошли хитрым путём. Сначала они записали, как пара людей играет вместе: один даёт команды, другой выполняет. Потом попросили игроков пересмотреть записи своих solo-сессий и вслух описать, что и зачем они делали. Так создавался «языковой слой» для игровых действий — своеобразный словарь намерений.
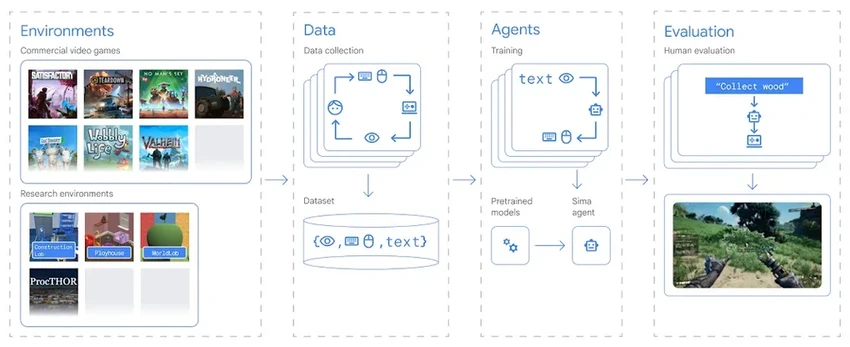
SIMA изнутри: как работает универсальный агент
SIMA — это не один монолитный алгоритм, а система моделей. Одни обрабатывают изображение с экрана, другие интерпретируют текстовые инструкции, третьи предсказывают последствия действий. Всё это обучено на данных из 3D-игр. Причём агенту не нужен доступ к «кухне» игры — её исходному коду. Ему достаточно всего двух потоков данных: картинки с монитора и ваших голосовых или текстовых команд. Он также понимает нажатия клавиш и движения мыши как способ взаимодействия с миром.
На сегодня SIMA оценивается по 600 базовым навыкам: от «поверни налево» до «откри карту». Он справляется с простыми задачами, которые решаются за 10 секунд. Но цель — куда амбициознее. Учёные хотят научить его сложному многоэтапному планированию. Чтобы по команде «Найди ресурсы и построй лагерь» он сам составил план и выполнил все шаги. Современные языковые модели умеют генерировать текстовые планы, но не умеют действовать. SIMA должен стать тем самым «исполнительным звеном».
Магия обобщения: секретная сила SIMA
Самое интересное в этом исследовании — феномен обобщения. Оказалось, что агент, обученный на множестве игр, гораздо гибче и сообразительнее того, кого тренировали только в одной среде. Более того, SIMA, который никогда не видел конкретную игру, но учился на других, показывает результат почти не хуже «узкого специалиста». Это и есть та самая универсальность — способность применять знания в совершенно новых условиях.
Пока до человеческого уровня понимания и адаптивности далеко, но вектор задан. Каждая новая игровая вселенная делает модель умнее и универсальнее. Конечная цель ясна: создать безопасных и полезных ИИ-агентов, которые понимают, чего мы от них хотим, и могут выполнить эти задачи — будь то в цифровом пространстве или, в отдалённой перспективе, в нашем физическом мире. Не слишком ли это смелая мечта? Время покажет.
В топе