Языковые модели для смартфона: как 1-битная архитектура экономит память и энергию
Любая нейросеть по сути — это огромный массив параметров, чисел, которые настраиваются в процессе обучения. Долгое время главным способом «похудеть» было снижение их точности: с 16 бит до 8, потом до 4. Но что, если дойти до предела — всего одного бита на параметр? Это как перейти от подробной карты местности к простым указателям «да» и «нет». Сложно? Да. Но возможно.
Мир, в котором параметр весит один бит

Есть два основных пути. Первый — обучить модель как обычно, а потом «ужать» её параметры, как архив на компьютере. Это посттренировочное квантование (PTQ). Второй путь — изначально учить модель так, чтобы она мыслила в этих сжатых категориях (QAT). Долгое время PTQ был фаворитом.
Именно этим путём пошла команда из Университета Бэйхан и Гонконга, создав метод BiLLM. Они «упаковали» подавляющее большинство параметров модели в 1 бит, но оставили чуть больше места (2 бита) для самых важных из них — тех, что сильнее всего влияют на качество ответов. В эксперименте им удалось так сжать модель LLaMA с 13 миллиардами параметров. Результат? Она стала чуть менее точной, но занимала в 10 раз меньше памяти. Согласитесь, для смартфона это отличный компромисс.
Революция уже началась

А что насчёт обучения с нуля? Команда Microsoft Research Asia в Пекине уже создала BitNet — первую 1-битную модель, обученную методом QAT. Она не отставала от «сжатых» коллег, хотя и проигрывала полномасштабным моделям. Зато её энергоэффективность была выше в 10 раз! Подумайте об этом: в десять раз меньше энергии на тот же интеллектуальный труд.
Затем появилась BitNet 1.58b. Её параметры могли быть -1, 0 или 1, что в среднем тратило около 1.58 бита на параметр. И вот сенсация: модель с 3 миллиардами параметров показала себя не хуже полноценной LLaMA аналогичного размера! При этом она была в 2.7 раза быстрее, потребляла на 72% меньше видеопамяти и экономила 94% энергии GPU. Цифры, от которых захватывает дух.
В этом году харбинские учёные представили свой гибридный метод OneBit, сочетающий оба подхода. Их сжатая 13-миллиардная модель почти догнала по качеству оригинальную LLaMA, занимая при этом вдесятеро меньше места. Тренд очевиден: маленькие модели учатся думать не хуже больших.
Зачем этому миру новые процессоры?
Преимущества сжатых моделей очевидны: они помещаются на компактные чипы, меньше грузят память и работают шустрее. Но есть загвоздка. Современное «железо», особенно GPU, заточено под работу с высокоточными числами. Основная энергозатратная операция в них — умножение параметров на входные данные.
А теперь представьте чип, созданный специально для 1-битного мира. Если параметр — это просто -1 или 1, то умножение не нужно! Вместо этого процессору достаточно будет делать простейшие сложение и вычитание. Экономия ресурсов станет колоссальной, особенно для моделей с триллионами параметров.
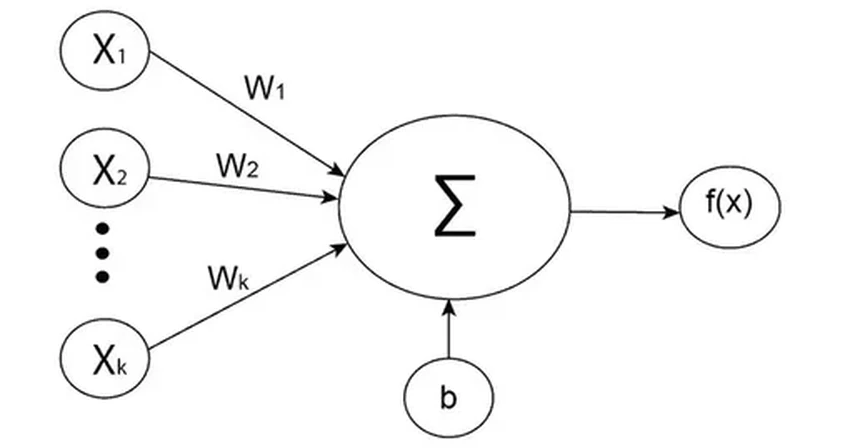
Таких чипов пока нет, но они неизбежны. Учёные уверены: как только 1-битные модели докажут свою состоятельность, аппаратная поддержка появится. И главной целью станет не суперкомпьютер, а устройство, которое есть у каждого из нас. Будущее, где ваш телефон обладает интеллектом целого дата-центра, начинается сегодня — с одного-единственного бита.
В топе