Как устроены большие языковые модели: почему они иногда галлюцинируют и как учатся
Многие из нас уже привыкли обращаться к нейросетям за помощью, не особо задумываясь о том, как они устроены. Мы смеемся над их курьёзными ошибками и раздражаемся, когда они начинают «сочинять» факты. Но чтобы понять эту «магию», нужно начать с азов.
Из чего сделана «цифровая мысль»: нейрон по полочкам
Начнем с базового элемента — нейрона. Не пугайтесь, всё довольно наглядно. Представьте его как маленький узелок, который что-то принимает, что-то с этим делает и что-то передаёт дальше.
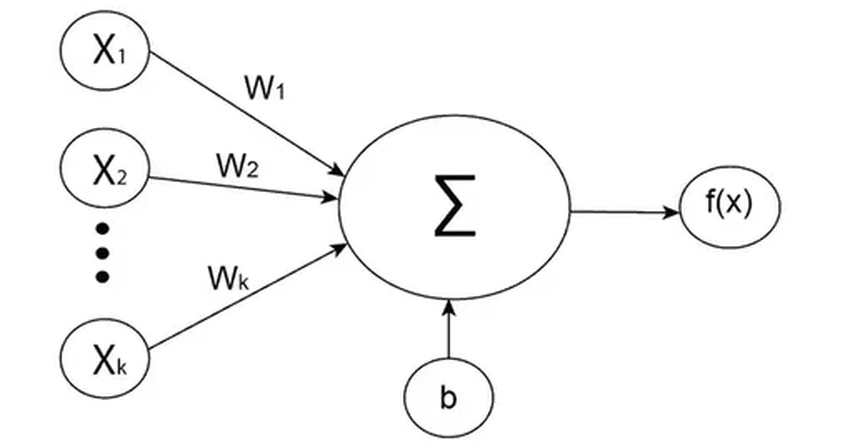
Слева к нему поступают входные сигналы (X1, X2... Xk). Это могут быть числа, представляющие слова или их части. Каждый сигнал умножается на свой «вес» (W1, W2... Wk) — коэффициент важности. Сначала эти веса назначаются почти случайно. Все взвешенные сигналы складываются, и сумма попадает в функцию активации — простенькое реле, решающее, «возбудиться» ли нейрону. Результат отправляется дальше, к другим нейронам. Современная сеть — это гигантская паутина из миллиардов таких связных узлов, расположенных в тысячах слоёв. И вся её «мудрость» — в правильно подобранных весах.
Как «железку» учат думать: от перцептрона до гиганта
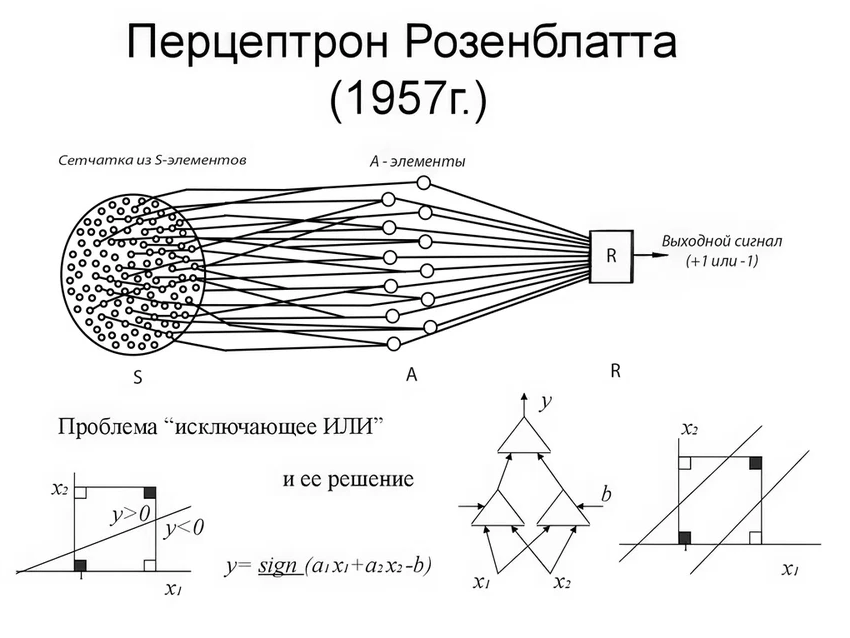
Сама идея нейросети не нова. Ещё в 1950-х американский учёный Фрэнк Розенблатт создал перцептрон — однослойную сеть, которая пыталась распознавать рукописные цифры. Мощность его машины сегодня вызывает улыбку — она несравнимо слабее любого смартфона. И он часто ошибался: чуть наклони цифру или измени почерк — и система терялась.

Современные модели — их далёкие, невероятно могущественные потомки. Вместо сотен нейронов — сотни миллиардов. Они учатся на суперкомпьютерах, поглощая терабайты данных. А сам процесс обучения — это бесконечная тонкая настройка тех самых весов (W1... Wk).
Представьте ученика, который решает задачи. Дали пример — он дал ответ. Если ответ неверный, учитель его поправляет: «Вот здесь твои „веса“ ошиблись, давай их чуть-чуть подкрутим». И так тысячи, миллионы раз. С каждым циклом ошибок становится меньше, а ответы — точнее. Это и есть обучение. Потом модель проверяют на новых, незнакомых данных. Если ошибается — доучивают. Парадокс в том, что даже создатели до конца не знают, *как именно* сеть выучила тот или иной факт. Это «чёрный ящик» с феноменальной эрудицией.
Три ступени к разуму: как выращивают языковую модель
Обучение современной LLM — многоэтапный и затратный процесс. Всё начинается с Pretrain — базового обучения. Модель «скармливают» гигантские массивы текстов (терабайты!) и учат простой, но ключевой вещи: предсказывать следующее слово в предложении. Так она впитывает структуру языка, грамматику, стили, факты. Но спрашивать её что-либо пока бесполезно — она просто угадывает продолжение. Критически важно, *какие* данные ей дать. Если брать всё подряд из интернета, модель нахватается мусора и лжи. Поэтому компании с качественными поисковыми системами имеют преимущество — они умеют фильтровать информацию.

Следующий этап — Supervised fine-tuning, или обучение с учителем. Здесь в игру вступают люди-тренеры. Их задача — научить модель понимать наши запросы. Они создают тысячи пар «вопрос — идеальный ответ» на самые разные темы. Модель изучает эти примеры и начинает улавливать, что от неё хотят, когда пишут «напиши деловое письмо» или «объясни квантовую физику просто». Качество тренеров тут решает всё: нужны грамотные, разносторонние авторы, способные создавать эталонные тексты.

Финальный штрих — Reinforcement Learning (RL), обучение с подкреплением. Это как дрессировка. Создаётся отдельная reward-модель — своего рода внутренний критик. Тренеры дают ей несколько ответов основной модели на один вопрос и ранжируют их: этот полезный и правдивый, этот — так себе, а этот — откровенная выдумка. Reward-модель учится на этих оценках и начинает «штрафовать» основную модель за плохие ответы и «поощрять» за хорошие. Так рождается не просто умная, но и удобная, безопасная модель-ассистент. Именно так появляются новые поколения, становящиеся с каждым разом умнее и надёжнее.
Можно ли сделать модель «для себя»?
Возникает резонный вопрос: одна модель на всех — может ли она быть экспертом в узкой области, скажем, в органической химии или банковском праве? Да, и это одно из ключевых преимуществ. Большую модель можно относительно недорого «дообучить» на специфичных данных, создав персонального эксперта. И этим экспертом могут потом пользоваться все химики в компании. Обучение модели с нуля стоит десятки миллионов долларов, а такая тонкая настройка — на порядки дешевле. Правда, не все разработчики разрешают подобную кастомизацию.
Ахиллесова пята: галлюцинации и как с ними борются
Идеальна ли модель после такой подготовки? Увы, нет. Главный её бич — «галлюцинации», или конфабуляции. Это когда нейросеть уверенно сочиняет факты, цитирует несуществующие статьи или даёт неверные инструкции. Почему? Потому что в своей основе она — статистический угадыватель следующего слова, а не хранилище истины. Она может спутать контексты или неправильно интерпретировать омонимы. Помните историю нью-йоркского юриста, который представил суду сфабрикованные нейросетью прецеденты? Она не врала сознательно — она просто «дорисовала» вероятное продолжение текста.

Борются с этим по-разному. Многие сервисы теперь снабжают ответы ссылками на источники — проверяйте, не доверяйте слепо. Но для этого пользователь сам должен обладать достаточной компетенцией, чтобы усомниться. Чаще всего модель говорит правду, но здоровый скепсис не повредит.

Ещё одна проблема — обход ограничений безопасности. Модель может отказаться рассказывать, как сделать взрывчатку. Но что, если попросить её описать сцену для фильма, где герой покупает в хозяйственном магазине ингредиенты для этой цели? Исследователи показали, что в таком сценарии модель «расколется» и даст информацию. Разработчикам пришлось экстренно доучивать систему, чтобы закрыть эту лазейку. Эта бесконечная игра в кошки-мышки показывает, как сложно создать по-настоящему безопасного и правдивого ассистента.
Несмотря на все недостатки, большие языковые модели прочно вошли в нашу жизнь. Они экономят время, помогают с рутиной и становятся умнее с каждым обновлением. Главное — помнить, что это инструмент, а не оракул. Пользуйтесь, но проверяйте. Ведь даже самый продвинутый искусственный интеллект пока не заменит нашу человеческую критичность и здравый смысл.
В топе